一、计算机中的显示原理 要想在计算机的显示器上显示文字,首先你得写一个程序,这个程序的任务就是就是把文字的显示信息发给显卡,显示信息包括在这个屏幕上的输出位置、字的大小等等。然后显卡就知道怎么显示这个字符了。
屏幕上是如何显示文字的原理是什么呢? 屏幕上其实有很多个小灯,小到肉眼看不见,当他们不亮时,屏幕就是黑色的,当他们亮了一部分,如果那一部分刚好是个文字的形状,那么屏幕上就显示文字了。这个原理就跟军训时人摆文字显示字符一样。如下图,通过led灯的开和关显示出了123。放到显示器上,小灯会变得特变小,肉眼很难看到,当一部分红色的小灯亮了,那一部分刚好摆成123的形状,那么红色的123这三个字符就在屏幕上显示出来了。

如何让显示器得知道是那个灯亮那个灯灭,这就是显卡的作用了,操作系统会根据文字的编码,去字库中找到要显示的字符的点阵数据,点阵数据指明了哪个灯应该亮起,亮起的颜色是什么颜色。显卡会结合点阵数据和其他显示信息,进行计算(比如按照一定比例扩大等),然后发给显示器控制显示器的显示! 注意:这一部分的具体细节我不确定,但是大概的思路应该是没错的。
通过以上得知,关键点在于文字的编码,只要知道了文字的编码,就能找到字库的点阵数据。众所周知,文字的编码有很多种,而乱码的根本原因是文件保存时采用的编码和打开文件时用于解码的编码不一致,从而找到了错误的点阵数据,显示了错误的输出!。
二、从键盘输入开始理解编码的存在形式 以window系统为例,假设你刚刚打开了记事本。 1.你在键盘上按下了’a‘。
2.你的按下触发了电路,键盘扫描到你a被按下,于是键盘形成了’a’的扫描码,发送到了存在于键盘上的寄存器,同时给CPU发送了一个中断信号,告诉CPU我这有活动了!
3.CPU根据键盘的中断线路号检测到是键盘发出的中断信号,于是根据中断号计算出键盘的中断处理程序在内存中的地址,转到键盘的中断处理程序去执行。
4.键盘的中断处理程序找到键盘的驱动程序代码,转到键盘的驱动程序执行。
5.键盘的驱动程序去读取键盘上的保存扫描码的寄存器,把‘a’的扫描码读到内存中。
6.驱动程序把扫描码转换成虚拟码。为什么要转换呢,因为不同的键盘由于厂家不同,型号不同、设计不同的原因,‘a’这个按键产生的扫描码在不同的键盘上是不一样的,为了统一管理,驱动程序得把不同键盘按下的‘a’转换成统一的表示。比如把不同键盘按下的‘a’产生的扫描码统一转换成一个字节的0x41。驱动程序要进行转换,那么驱动程序得知道这是哪种类型的键盘,不然没有转换的依据,原理是键盘的相关信息比如生产厂家、键盘型号等会保存在键盘上的一些只读寄存器中,计算机通过这些只读寄存器就知道这是哪种键盘。从而就知道该键盘的扫描码对应的虚拟码。
7.驱动程序把0x41交给操作系统上自带的且在后台默默运行的的IMM进程。
8.IMM进程把0x41交给系统当前使用的的输入法编辑器。比如搜狗输入法或者百度输入法。系统上所有的输入法,都由IMM管理。
9.输入法收到了0x41,对0x41进行处理,霹雳巴拉一顿操作,首先查到0x41这个值对应的可能的文字,比如可能是‘啊’、‘阿’、‘吖‘…等。首先查询系统当前的代码页是哪一个,也就是系统默认编码,若你没有修改系统的默认编码,则查找的结果为GBK(相当于GB2312)编码的。于是通过GBK的代码页这些可能的文字的GBK编码找出来,通过操作系统从字库中寻找这些可能文字的字库数据,交给显卡,显卡把他们显示出来。
10.显卡把他们显示出来后,屏幕上显示了好多个文字让你选择,那么你通过键盘的左移右移回车等操作选中了一个字,这个键盘操作又产生扫描码,最后还是输入法接收到了你的键盘按键输入情况,然后,输入法就可以根据你的键盘输入情况确定你选中了哪个文字,假设你选中了’啊’,于是输入法把‘啊’这个字的GBK码交给操作系统,操作系统把这个GBK码放进指定内存中,这指定内存被称为输入缓冲区。
11.记事本可以扫描缓冲区有没有内容,当检测到了缓冲区有了内容后,记事本至少需要两个操作,一是把‘啊’这个文字显示到记事本的窗口里面,二是把"啊"的编码放到自己的内存空间。
12.记事本接收到的是GBK编码,这个编码保存在了记事本的内存空间,并把“啊”输出到了记事本的窗口中。这时你的输入操作已经结束了(如果你不再进行输入),接下来就是保存这个记事本的内容了,如果想要保存这个“啊”,你的应用程序就得向操作系统申请一个文件,把“啊”的编码写进文件中。如果你不作任何操作,硬盘上就会默认保存的是‘啊’的GBK编码,如果你想保存的是’啊’的其他编码,那也可以,转换一下编码格式,然后放进文件中保存。放进文件中保存,那c语言来说,有二进制方式的写和文本文件方式的写,该用什么方式呢?首先说明什么是文本文件,文本文件就是保存文本的文件,里边都是一些字符(也就是文本)的编码,解析出来后都是文字,你用utf-8格式保存的,里边就是utf-8格式的字符的编码,你用GBK格式保存的,里边就是GBK的编码,总之里边保存的是文字信息。另一个就是二进制文件,一般来说我们编程很少用到。二进制文件里边保存到不是文本,比如视频文件、图片文件、3D模型等。其实二进制文件和文本文件在文件中的保存形式都是0和1的二进制流,既然都是0和1的二进制流,为什么要区分他们呢,因为他们有点区别,比如文本文件以EOF(值为-1)作为文件结束标志,因为不管是什么编码,都没有哪个字符的编码值是-1。而二进制流就不一样了,里边完全有可能有一段字节代表着-1,因此不能以-1作为文件的结束标志,一般来说二进制文件应该是通过比较文件长度来判断结束标志的。在c语言中,我们通常是使用fwrite()和fread()函数来读写文件,那么我们并没有指明以什么编码方式来读出或写进文件啊,别忘了,两个函数会是系统调用相关的,而系统默认的编码格式就是GBK,因此这两个函数都是按GBK来进行读或取的。如果你想使用其他编码比如UNICODE,就得使用其他读写的函数了,比如fgetwc()、fwscanf();这些函数会把GBK编码转换成UNICODE编码再进行读和写。
13.记事本默认保存的编码是ANSI,ANSI也叫多字节字符集,ANSI其实不是一种编码方式,是所有使用不定长字节来表示字符的编码格式的统称,在简体中文Windows操作系统上,ANSI指的是GBK编码,在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 JIS 编码。当然你用可以更改记事本的保存格式。Unicode同理,Unicode是一个字符集,不是一个编码方式,在windows这边,Unicode指的是UTF-16,在其他环境下,可能指的是UTF-8或UTF-32,比如linux上指的是utf-8.
|
|
|
|
|
三.缕一缕编程的过程
1.首先,现在我们简化一下VS2013这个软件,把VS2013看成是记事本(编辑器)+编译器的结合体。它只有编写文本进行保存和对文本文件进行编译的功能。如果你使用的是中文操作系统的Windowsd的VS2013编写源代码,在你编写完成后,运行之前或者按下CTRL+S,那么你的源代码就会保存起来。跟记事本的保存一样,那么它默认应该是使用GBK编码格式来保存你的代码源文件,那我不想按GBK来保存怎么办呢?可以在文件->高级配置选项里修改源代码的保存格式。
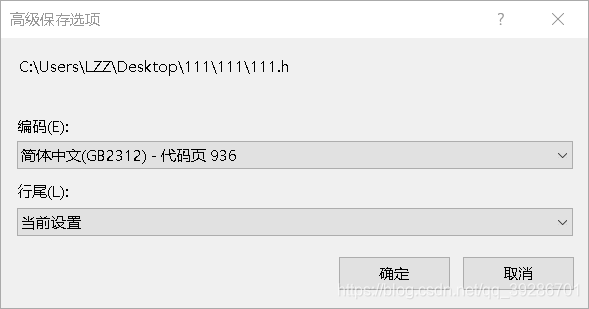
2.假设你的源代码里有一个字符"你好",在你把你的源代码保存了之后,硬盘上你的源代码文件中存在着"你好,世界!“的GBK编码:C4E3(你) BAC3(好) 。
3.你的打印文件里面有打印"你好"这个中文字符的语句,你想在屏幕上显示"你好”
4.你点击了运行按钮,首先,编译器的做的工作就是启动它的编译器对你的源代码进行编译,要进行编译,首先得解析源代码文件,要解析一个文件,得先知道它是什么编码,否则解析要出错啊,那么编译器是按什么编码格式来解析你的源文件呢,不用想就知道,那肯定是GBK编码嘛,毕竟编辑器的默认编码就是GBK的。那我要是把编辑器的编码格式换了怎么办呢,没事,编译器改成一样的不就完事了。修改的方式为项目 -> 属性 -> 配置属性 -> c/c++ -> 命令行 -> 其他选项。在其他选项里输入你所需要的编码,比如utf-8。
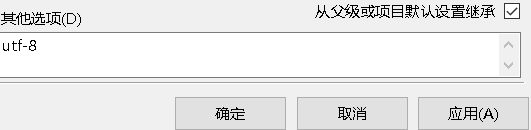
一般这一行是空的,我们只需把“从父级或项目默认设置继承”选上就好了。这样它就会根据你项目的编码格式主动更改相同的编码进行解析。
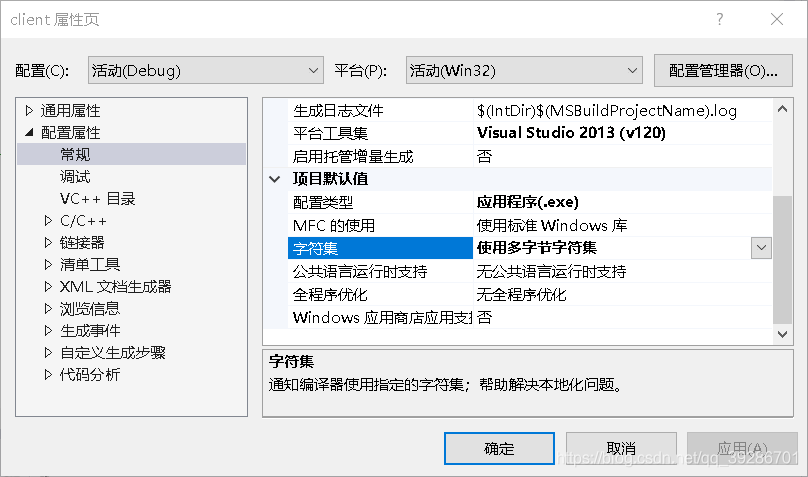
4.等等,你好像记得有个地方也能修改项目的编码属性?就在项目 -> 属性 -> 配置属性 -> 常规 ->字符集那,有个使用多字节字符集和使用Unicode字符集?它默认也不是GBK啊,它默认是Unicode呢。这又是什么玩意?首先,在这里,多字节字符集=ANSI=GBK,Unicode=utf-16。这玩意是这样的,它不是设置你写的代码的编码格式,但是他能控制你使用的API的版本。什么意思呢?你写的程序肯定有#include<“xxx”>的代码,#号说明这是一个预编译命令,c语言里可没有#这个操作符。预编译命令是给编译器看的,编译器检测到了预编译命令后,在链接的时候就会把#include<“xxx”>删掉,把#include<“xxx”>原本的代码复制过来放到这个地方。预编译指令还有一个较为常见的就是#ifndef。完整意思就是if not define,字面上来理解就是如果没有定义。而在vs上编程你经常#incluide<“xxx”>里边的代码里经常有和以下类似的代码: ifndef Unicode typedef MessageBox MessageBoxA #endif typedef MessageBox MessageBoxW
翻译如下: 如果没有定义 Unicode MessageBox 就是MessageBoxA 结束 MessageBox 就是 MessageBoxW
也就是说,默认情况下(也就是字符集是Unicode),你在代码里使用MessageBox函数编译器就把MessageBox替换为MessageBoxW,如果你在字符集里把"使用Unicode字符集"改成"使用多字节字符集",那么MessageBox就被编译器替换为MessageBoxA!实际上,代码库里根本没有MessageBox这个函数!MessageBoxA和MessageBoxW有什么区别呢,MessageBoxA是处理ANSI也就是GBK的,MessageBoxW是处理Unicode的,这两个函数处理逻辑也是不一样的,处理GBK的编码,得先判断内存中保存的数据是一个字节的还是两个字节的,若是一个字节的(英文),就一次从内存中读取一个字节,若是两个字节的,就一次从内存中读取两个字节,两个字节的最高位第八位一定是1,所以比较容易判断。处理Unicode的比较简单,主要是每次读取的字节数数跟GBK的不一样,且如果要在屏幕上显示的话,还得经过转码,转成GBK的。
5.在上边我们提到,字符"你好",在硬盘中的源代码文件中的存在形式是GBK编码:C4E3(你) BAC3(好) ,那么想要正确的从内存中处理C4E3 BAC3(程序在运行时操作系统会把它从硬盘加载到内存),即把它按照一次读两个字节且显示在屏幕上,你只能使用MessageBoxA这个函数,你可以直接使用MessageBoxA,也可以写MessageBox,但是如果你写MessageBox,你就得把字符集改成使用多字节字符集。如果你使用MessageBoxW对这两个字符进行处理,那么MessageBoxW会认为C4E3 BAC3是Unicode字符,而当前系统的默认字符集是GBK,它会把C4E3 BAC3转换成对应的GBK字符,然后通过操作系统进行输出,本来C4E3 BAC3就是正确的了,再经过转换,不乱码才怪呢。要想使用MessageBoxW输出正确的文字,那么你在源代码里就应该这样定义字符串:TEST(“你好”),或者:L"你好“,这样编译器在处理这个字符串时,就不会按照GBK的编码把”你好“两个字按照C4E3 BAC3放进编译好的可执行文件了,而是会转换成Unicode的,这样MessageBoxW就能正确处理了。但是要明白,即使你加了TEXT,中文的”你好"的存在形式是这样的:
源代码(GBK)–>可执行文件(Unicode)
即在保存成源代码的时候,还是默认按照GBK来保存,编辑器可不管你什么TEXT不TEXT的,因此编译器还是按照GBK来读,但是编译器看到了带TEXT的字符串,它就会把TEXT中的字符串从GBK编码转换成Unicode编码的了,编译器进行处理也就是编译后形成的可执行文件里面的“你好”数据就是Unicode编码的。 总之,得明白了在中文字符在源文件中的编码和在可执行文件中的编码,以及源文件是谁按什么编码保存的,谁按什么编码解析读取的。
5.如何找到乱码源头。 一是检查保存格式,二是检查编译格式,三检查系统编码格式,这三个一定要整齐画一。四是检查函数有没有用对,比如在mfc编程中带W的和带A的。 以上前三步默认情况都是不会错的,除非被更改过。 还有一种字符叫宽字符,比如wchar,wspring等。定义宽字符时效果也同加了TEXT,编译软件会改成Unicode的。或者说初始化宽字符时字符得加TEXT或L。比如wchar_r ch1 = L‘A’,普通的char数组也可以保存汉字,只是两个字节表示一个汉字(gbk编码,其他编码可能是三个字节),打印输出时,格式化方式得是两个%c连在一起,既%c%c,表示从该char数组中去取两个字符作为一个汉字进行输出。
这在其他语言上也是行得通的,比如Python解释器默认是按utf-8来对源代码进行解码,当你使用记事本写python代码,且文件按ansi格式保存,执行的时候那就是乱码了。 注意,大部分的编码格式都兼容ascll,所以即便是编码不匹配,英文还是能正常被解析。
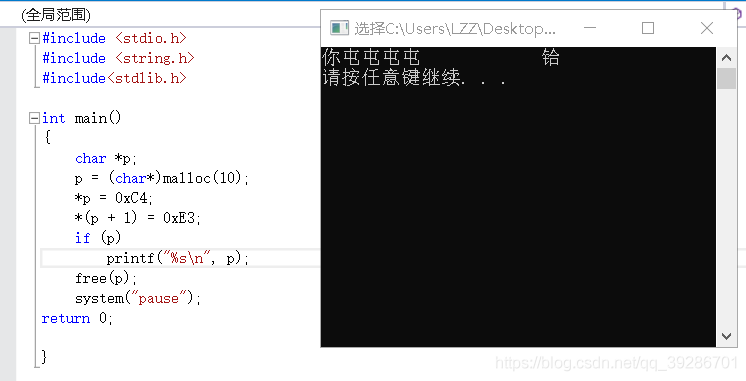
6.关于烫屯锟斤拷,诺诺诺 6.1 烫 ”烫“出现的原因是你试图输出一个未经初始化的字符数组。或者说栈内存未经初始化。
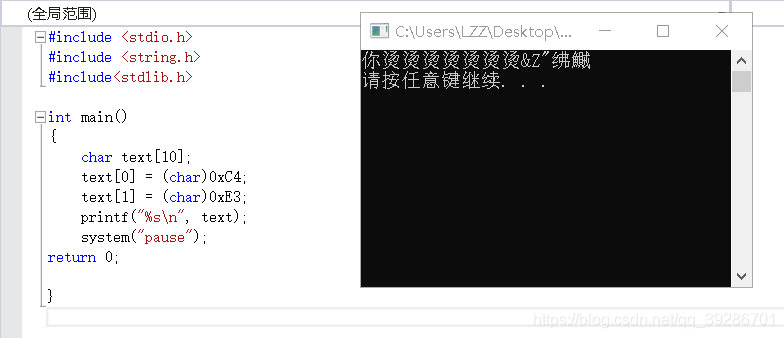
从上图我们可以看到,text字符数组我们只初始化了前两个字节,后面的字节是未经初始化的,那么按照惯例,未经初始化的变量应该默认为NULL才对,也就是不会打印出来,但是vs的编译器在Debug模式下,会把未初始化的栈内存赋值为CC,而不是我们以为的NULL了,0xCC按照GBK编码读出来就是”烫“

printf()函数首先会读到第一个字节,也就是C4,算出最高位是1,于是明白这不是一个英文字符,于是继续读下一个字节,读到了E3,于是把C4E3当成一个字符来输出,也就是“你”。继续读下一个字节,读到的是CC,最高位还是1,那就再读一位,两个字节CCCC当成一个字节就是“烫”,然后继续…,后面5个字符怎么乱套了我也不是很清楚。
6.2 屯 “屯”出现的原因是堆未经过初始化,你却想把堆中的内容打印出来。 我们申请内存都是在堆区开辟的,内存分为几块区域,代码区,放代码,顺序执行,数据区,放你定义的数据。栈区,当使用栈的时候在这块内存区域生成一个栈,函数调用会把数据压到栈,定义一个栈也很简单,首先在内存中找一个起始地址,记录在寄存器上,然后再使用一个寄存器记录栈顶的位置,几个字节的数据进来,栈顶位置变大几个字节,数据出去,栈顶位置变小,一个栈就搭建好了。之后是堆,你在代码中动态申请的内存,都会在堆这一块内存区域的某个位置给你申请。
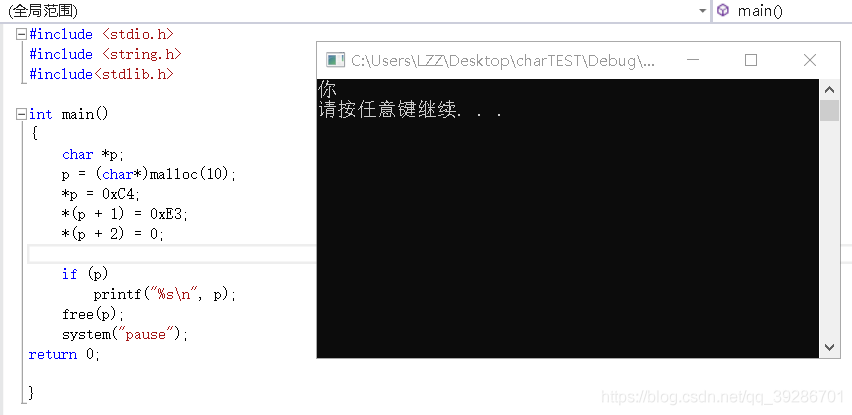
原理跟“烫”差不多,只是编译器默认把堆区的内容初始化为0xcd.
解决办法很简单,养成初始化的好习惯就好了,初始化为0就可以了。
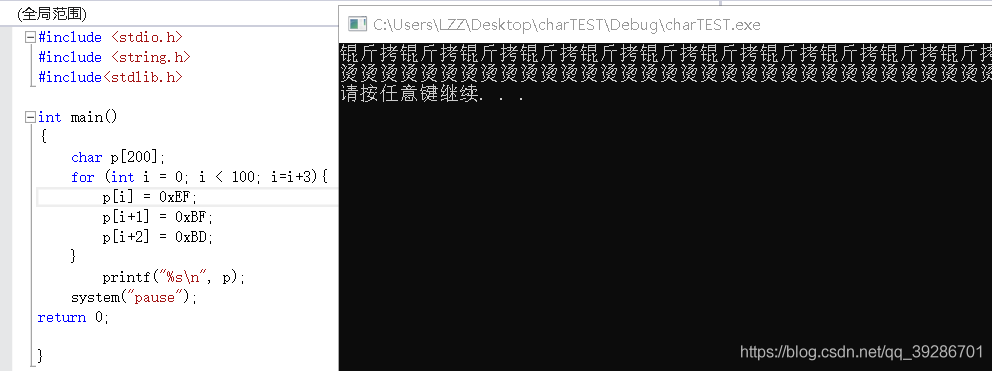
上图可以看出,我只把第三个字节初始化为0,后面几个字节并没有经过初始化,编译器还是默认给他们赋值为0xCD,但是当printf函数读到了第三个字节0,它就以为这个字符串已经结束了,也就不再输出后面的“屯”了。但是我们平常编程中还是要把申请的内存完全初始化比较稳妥。
6.3 琨斤拷 锟斤拷是不同编码的字符转换中转换失败导致的,当你想把某种编码通过编码转换工具转换成目前广泛流行的utf-8编码,然后编码转换工具就会根据原编码在对照表中查找(或者通过计算)对应的utf-8编码,但是编码转换工具找不到啊,它发现这两种编码根本不能转换,那怎么办呢,那就统一给他们一个默认编码吧,这个默认编码是0xEFBFBD(三个字节),于是内存中就会出现大量的EFBFBDEFBFBDEFBFBDEFBFBD… 然后我们按照GBK的来读,我们知道,GBK是按照一个字节或者两个字节来读的,上面的字符明显不是ascll,于是printf函数会两个字节两个字节的读。首先读前两个字节EFBF(琨),再往下读两个字节BDEF(斤),再往下读两个字节BFBD(拷),再往下两个字节EFBF(琨)…
上图中有一部分没有被初始化到,所以就“烫”起来了!
6.4 诺 “诺”好像是bom的原因,目前不是很理解。
以上纯属个人理解,如有错误,希望能指出!
参考链接: 使用char字符实现汉字处理
printf,wprintf与setlocale,char与wchar_t区别
转载自:CSDN